El mundo digital avanza a pasos agigantados y, con él, la necesidad de soluciones de almacenamiento más flexibles, escalables y accesibles. ¿Te has preguntado alguna vez cómo las grandes empresas gestionan cantidades masivas de información sin colapsar sus sistemas? La respuesta está flotando sobre nuestras cabezas, literalmente. Las bases de datos en la nube han revolucionado la forma en que almacenamos, procesamos y accedemos a la información, democratizando el acceso a tecnologías que antes solo estaban al alcance de corporaciones con grandes presupuestos.
La migración hacia infraestructuras basadas en la nube no es una simple tendencia pasajera, sino una transformación fundamental en la arquitectura de sistemas de información. Empresas de todos los tamaños están abandonando sus centros de datos físicos para sumergirse en el océano de posibilidades que ofrecen proveedores como AWS, Google Cloud y Microsoft Azure. Y no es para menos, cuando los beneficios saltan a la vista: reducción de costos operativos, mayor disponibilidad, escalabilidad prácticamente ilimitada y la posibilidad de acceder a herramientas avanzadas de análisis de datos sin necesidad de inversiones millonarias.
Tabla de contenidos
- Bases de Datos en la Nube: Fundamentos Esenciales
- Características de las Bases de Datos en la Nube
- Tipos de Bases de Datos en la Nube
- Ventajas y Desventajas de las Bases de Datos en la Nube
- Implementación Exitosa de Bases de Datos en la Nube
- Tendencias Futuras en Bases de Datos en la Nube
- Preguntas Frecuentes sobre Bases de Datos en la Nube
- 1. ¿Cuál es la diferencia entre bases de datos en la nube y bases de datos tradicionales?
- 2. ¿Qué tipo de base de datos en la nube debería elegir para mi proyecto?
- 3. ¿Son seguras las bases de datos en la nube para información sensible?
- 4. ¿Cómo afecta la latencia de internet al rendimiento de bases de datos en la nube?
- 5. ¿Qué consideraciones regulatorias debo tener en cuenta al migrar a bases de datos en la nube?
- 6. ¿Cómo puedo estimar y controlar los costos de bases de datos en la nube?
- Casos de Éxito en la Implementación de Bases de Datos en la Nube
- Estrategias de Migración a Bases de Datos en la Nube
- Conclusión: El Futuro de los Datos Empresariales en la Nube
Bases de Datos en la Nube: Fundamentos Esenciales
Las bases de datos en la nube representan un paradigma revolucionario en el almacenamiento y gestión de datos. A diferencia de las soluciones tradicionales alojadas en servidores locales, estos sistemas operan completamente en infraestructuras remotas mantenidas por proveedores especializados. ¿Pero qué implica exactamente este cambio de enfoque?
En su esencia, una base de datos en la nube es un servicio que permite almacenar, gestionar y acceder a información estructurada a través de internet. El proveedor del servicio se encarga de todos los aspectos relacionados con el hardware, las actualizaciones de software, la seguridad y las copias de seguridad, liberando a las organizaciones de estas responsabilidades técnicas.
La arquitectura típica de estos sistemas incluye múltiples capas de abstracción que separan los datos físicos de las aplicaciones que los utilizan. Esta separación proporciona ventajas significativas en términos de flexibilidad y resiliencia. Por ejemplo, si un servidor físico falla, el sistema puede redirigir automáticamente las solicitudes a otro servidor sin interrupciones para el usuario final.
Otra característica fundamental es el modelo de responsabilidad compartida. Mientras que el proveedor garantiza la disponibilidad y funcionamiento de la infraestructura, la organización cliente mantiene el control sobre sus datos y las políticas de acceso. Esta división clara de responsabilidades permite a cada parte centrarse en lo que mejor sabe hacer.
La evolución de las bases de datos en la nube ha sido vertiginosa. Desde los primeros servicios que simplemente replicaban bases de datos relacionales en servidores remotos, hemos pasado a soluciones nativas de la nube diseñadas específicamente para aprovechar al máximo las características únicas de estos entornos, como la elasticidad y la distribución geográfica.
Los modelos de implementación también han evolucionado, ofreciendo ahora opciones como:
- Bases de datos como servicio (DBaaS): Soluciones completamente gestionadas donde el proveedor se encarga de toda la administración.
- Despliegues híbridos: Combinan infraestructuras locales con servicios en la nube para obtener lo mejor de ambos mundos.
- Multi-nube: Utilizan servicios de varios proveedores para evitar la dependencia de un único vendedor.
Esta flexibilidad permite a las organizaciones adaptar su estrategia de bases de datos a sus necesidades específicas, presupuesto y requisitos de cumplimiento normativo.
Características de las Bases de Datos en la Nube
Las bases de datos en la nube poseen características distintivas que las separan claramente de sus contrapartes tradicionales. Estas propiedades no solo definen su funcionamiento técnico, sino que también determinan su valor estratégico para las organizaciones modernas.
Elasticidad Dinámica
Una de las características más revolucionarias es la capacidad de escalar recursos automáticamente según la demanda. ¿Experimentas un pico repentino de tráfico? Los sistemas en la nube pueden asignar más capacidad de procesamiento y almacenamiento en cuestión de segundos. Cuando la demanda disminuye, los recursos se liberan, optimizando costos. Esta elasticidad dinámica elimina la necesidad de sobredimensionar sistemas para cubrir picos ocasionales, permitiendo un modelo económico basado en el consumo real.
Alta Disponibilidad Geográfica
Las bases de datos en la nube típicamente operan en múltiples centros de datos distribuidos globalmente. Esta arquitectura distribuida garantiza que los datos permanezcan accesibles incluso ante fallos regionales o desastres naturales. Los proveedores líderes ofrecen SLAs (Acuerdos de Nivel de Servicio) con disponibilidades superiores al 99.99%, algo prácticamente imposible de lograr con infraestructuras locales convencionales.
Autogestión y Automatización
La mayoría de servicios de bases de datos en la nube incorporan capacidades avanzadas de autogestión. Tareas tediosas como la optimización de índices, la gestión de almacenamiento o las copias de seguridad se realizan automáticamente, reduciendo la carga operativa de los equipos de TI. Algunas plataformas incluso utilizan inteligencia artificial para predecir problemas potenciales y aplicar medidas correctivas antes de que afecten al rendimiento.
Modelos de Consistencia Flexibles
A diferencia de las bases de datos tradicionales que suelen ofrecer un único modelo de consistencia, las soluciones en la nube permiten elegir entre diferentes opciones según las necesidades de cada aplicación. Desde consistencia fuerte para aplicaciones que requieren precisión absoluta (como sistemas financieros) hasta modelos de consistencia eventual que priorizan la disponibilidad y rendimiento en aplicaciones que pueden tolerar cierta latencia en la sincronización de datos.
Integración Nativa con Servicios Complementarios
Las bases de datos en la nube no operan como islas aisladas, sino como parte de ecosistemas más amplios. La integración nativa con servicios de análisis de datos, aprendizaje automático, IoT o procesamiento de eventos en tiempo real multiplica su valor, permitiendo construir soluciones completas sin necesidad de complejas integraciones personalizadas.
Seguridad Multicapa
La protección de datos en la nube implementa múltiples capas de seguridad, incluyendo:
- Cifrado en reposo y en tránsito
- Controles de acceso granulares basados en identidad
- Aislamiento de red configurable
- Auditoría continua de actividades
- Protección contra ataques DDoS
- Cumplimiento certificado con estándares internacionales
Esta aproximación integral a la seguridad suele superar las capacidades de protección que la mayoría de organizaciones pueden implementar internamente.
Facturación Basada en Consumo
El modelo económico de pago por uso representa una transformación fundamental en la forma de adquirir tecnología. En lugar de grandes inversiones iniciales en hardware y licencias, las organizaciones pagan únicamente por los recursos que realmente utilizan, convirtiendo gastos de capital en gastos operativos más predecibles y alineados con el valor generado.
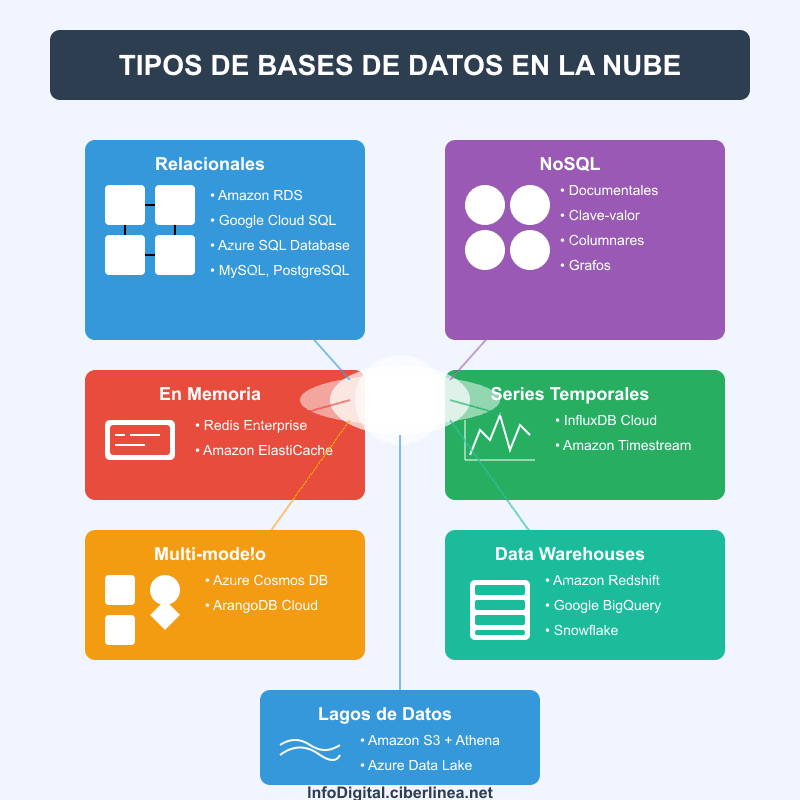
Tipos de Bases de Datos en la Nube
El ecosistema de bases de datos en la nube es notablemente diverso, ofreciendo soluciones especializadas para diferentes tipos de datos y patrones de uso. Comprender esta diversidad resulta fundamental para seleccionar la herramienta adecuada según las necesidades específicas de cada proyecto.
Bases de Datos Relacionales en la Nube
Las bases de datos relacionales continúan siendo la columna vertebral de muchas aplicaciones empresariales, y su migración a la nube ha sido una evolución natural. Servicios como Amazon RDS, Google Cloud SQL y Azure SQL Database ofrecen versiones gestionadas de motores tradicionales como MySQL, PostgreSQL, SQL Server y Oracle. Estas soluciones mantienen la potencia y consistencia del modelo relacional mientras añaden beneficios propios de la nube como alta disponibilidad automática, escalabilidad simplificada y gestión automatizada de copias de seguridad.
Son ideales para aplicaciones que requieren transacciones ACID, consultas complejas y esquemas de datos bien definidos, como sistemas ERP, CRM y aplicaciones financieras.
Bases de Datos NoSQL
Las bases de datos NoSQL nacieron prácticamente junto con la revolución de la nube, diseñadas específicamente para casos de uso donde las bases relacionales tradicionales muestran limitaciones. Se dividen en varias categorías:
- Documentales: Como MongoDB Atlas o Amazon DocumentDB, almacenan información en formato similar a JSON, ideal para datos semiestructurados con esquemas variables.
- Columnares: Como Google Bigtable o Azure Cosmos DB, optimizadas para consultas analíticas sobre grandes volúmenes de datos.
- Clave-valor: Como Redis Cloud o Amazon DynamoDB, extremadamente rápidas para operaciones simples basadas en identificadores únicos.
- Grafos: Como Neo4j Aura o Amazon Neptune, especializadas en relaciones complejas entre entidades, perfectas para redes sociales, sistemas de recomendación o detección de fraude.
La flexibilidad de esquema, la escalabilidad horizontal y la optimización para patrones de acceso específicos hacen que estas bases de datos sean excelentes para aplicaciones web modernas, análisis en tiempo real y servicios que manejan datos heterogéneos.
Bases de Datos en Memoria
Servicios como Redis Enterprise Cloud o Amazon ElastiCache mantienen todos los datos en memoria RAM en lugar de almacenamiento persistente. Esta aproximación proporciona velocidades de respuesta extremadamente rápidas, medidas en microsegundos, ideales para casos como cachés de aplicación, gestión de sesiones, colas de mensajes y análisis en tiempo real.
Aunque tradicionalmente la volatilidad de la memoria era una limitación, las implementaciones modernas en la nube incorporan mecanismos de persistencia y replicación que garantizan la durabilidad de los datos.
Bases de Datos de Series Temporales
Diseñadas específicamente para gestionar datos secuenciales ordenados cronológicamente, soluciones como InfluxDB Cloud o Amazon Timestream optimizan el almacenamiento y consulta de mediciones que cambian con el tiempo. Son particularmente útiles para monitorización de infraestructuras, aplicaciones IoT, análisis financiero y cualquier escenario que implique analizar tendencias temporales.
Bases de Datos Multi-modelo
Una tendencia emergente son las bases de datos que soportan múltiples modelos de datos dentro de un único sistema. Servicios como Azure Cosmos DB o ArangoDB Cloud pueden funcionar simultáneamente como bases documentales, de grafos, columnares o clave-valor, permitiendo a los desarrolladores utilizar el modelo más adecuado para cada aspecto de la aplicación sin necesidad de gestionar sistemas independientes.
Data Warehouses en la Nube
Plataformas como Amazon Redshift, Google BigQuery o Snowflake representan la evolución de los almacenes de datos tradicionales al entorno cloud. Diseñados para análisis a gran escala, permiten procesar petabytes de información con consultas SQL complejas en tiempos sorprendentemente cortos. Su arquitectura separada para computación y almacenamiento permite escalar estos recursos independientemente, optimizando costos según las necesidades específicas de cada organización.
Lagos de Datos (Data Lakes)
Servicios como Amazon S3 combinados con Amazon Athena, o Azure Data Lake Storage con Azure Synapse, permiten almacenar cantidades masivas de datos en su formato natural (estructurados o no) y analizarlos bajo demanda con diversas herramientas. Este enfoque ofrece máxima flexibilidad para organizaciones que necesitan preservar todos sus datos para análisis futuros sin necesidad de transformarlos previamente.
Ventajas y Desventajas de las Bases de Datos en la Nube
La adopción de bases de datos en la nube conlleva una serie de beneficios significativos, pero también presenta desafíos que deben considerarse cuidadosamente. Analicemos en profundidad ambos aspectos para formar una visión equilibrada.
Ventajas Competitivas
Reducción drástica de costos iniciales: La eliminación de inversiones en hardware, licencias y centros de datos puede suponer ahorros iniciales de hasta un 70%. El modelo de pago por uso convierte grandes gastos de capital en costos operativos predecibles y alineados con el crecimiento del negocio.
Escalabilidad sin precedentes: Las bases de datos en la nube pueden crecer desde unos pocos gigabytes hasta petabytes sin interrupciones ni rediseños arquitectónicos. Esta elasticidad permite a startups y empresas emergentes utilizar la misma tecnología que grandes corporaciones, pagando solo por lo que necesitan en cada momento.
Disponibilidad global inmediata: Desplegar una base de datos con presencia mundial solía requerir años de planificación e inversiones millonarias. Hoy, servicios como Aurora Global Database de AWS o Cosmos DB de Microsoft Azure permiten configurar replicación en múltiples regiones con unos pocos clics, reduciendo la latencia para usuarios internacionales y garantizando continuidad ante desastres regionales.
Acceso a tecnologías avanzadas: Los proveedores de nube invierten constantemente en innovación, ofreciendo acceso a capacidades que serían prohibitivas de desarrollar internamente. Funcionalidades como aprendizaje automático integrado, procesamiento de lenguaje natural o análisis predictivo están ahora al alcance de organizaciones de cualquier tamaño.
Gestión simplificada: La automatización de tareas rutinarias como copias de seguridad, aplicación de parches y monitorización libera a los equipos técnicos para centrarse en actividades de mayor valor. Un estudio de IDC estima que las organizaciones pueden reducir hasta un 60% el tiempo dedicado a administración de bases de datos mediante soluciones cloud.
Agilidad empresarial mejorada: La capacidad de aprovisionar nuevos entornos en minutos en lugar de semanas o meses acelera dramáticamente los ciclos de desarrollo e innovación. Esta velocidad se traduce en ventajas competitivas tangibles en mercados donde la rapidez de adaptación resulta crucial.
Desafíos a Considerar
Dependencia de la conectividad: El acceso a bases de datos en la nube requiere conexión a internet estable y de baja latencia. Aunque existen soluciones híbridas con capacidades offline, las interrupciones de conectividad pueden afectar la disponibilidad de los sistemas.
Costos a largo plazo potencialmente mayores: Si bien los costos iniciales son menores, algunas organizaciones descubren que, tras varios años de uso intensivo, el costo acumulado puede superar al de infraestructuras propias. Un análisis financiero detallado que considere el ciclo de vida completo resulta esencial.
Preocupaciones sobre soberanía de datos: Las regulaciones de protección de datos cada vez más estrictas (como GDPR en Europa o LGPD en Brasil) imponen requisitos sobre la ubicación física de la información. Aunque los principales proveedores ofrecen regiones en múltiples países, algunas organizaciones enfrentan restricciones legales que complican la adopción cloud.
Complejidad en la migración: Trasladar bases de datos existentes a la nube puede resultar complejo, especialmente para sistemas legacy con décadas de desarrollo. La migración suele requerir adaptaciones arquitectónicas, refactorizaciones de código y periodos de coexistencia que añaden complejidad técnica y organizativa.
Riesgo de bloqueo con proveedores (vendor lock-in): La integración profunda con servicios específicos de un proveedor puede dificultar futuras migraciones. Aunque existen estrategias para mitigar este riesgo (como arquitecturas multi-nube o uso de abstracciones), requieren planificación deliberada desde fases tempranas.
Modelo de responsabilidad compartida: La seguridad en la nube funciona como un modelo de responsabilidad compartida donde el proveedor asegura la infraestructura, pero el cliente sigue siendo responsable de la configuración adecuada, gestión de accesos y protección de datos. Esta división a veces genera confusión y puede crear vulnerabilidades si no se gestiona correctamente.
Visibilidad y control reducidos: Las abstracciones que simplifican la gestión también pueden limitar la visibilidad sobre el funcionamiento interno de los sistemas. Para organizaciones con requisitos especializados de rendimiento o cumplimiento, esta relativa «caja negra» puede resultar problemática.
Implementación Exitosa de Bases de Datos en la Nube
La transición hacia bases de datos en la nube requiere un enfoque metódico que maximice los beneficios mientras minimiza los riesgos inherentes. Una implementación exitosa no se limita a aspectos técnicos, sino que abarca también dimensiones organizativas, económicas y de gestión del cambio.
Evaluación y Planificación Estratégica
Antes de migrar el primer byte, es fundamental realizar una evaluación exhaustiva del entorno actual y definir objetivos claros. ¿Buscas principalmente reducción de costos, mayor agilidad, o capacidades avanzadas? Las prioridades determinarán decisiones críticas como la selección de proveedores y el modelo de implementación.
Desarrolla un inventario detallado de bases de datos existentes, categorizándolas según criticidad, patrones de acceso, requisitos de rendimiento y dependencias. Esta catalogación permitirá priorizar migraciones y seleccionar las soluciones más adecuadas para cada caso.
Considera también implicaciones regulatorias y requisitos de cumplimiento específicos de tu industria. Sectores como finanzas, salud o administración pública suelen tener restricciones particulares sobre localización y tratamiento de datos que influirán en tu estrategia.
Selección del Modelo Adecuado
Existen diversos enfoques para implementar bases de datos en la nube, cada uno con diferentes equilibrios entre control, responsabilidad y simplicidad:
- Lift-and-shift: Migración directa de sistemas existentes con cambios mínimos. Ofrece resultados rápidos pero puede desaprovechar beneficios nativos de la nube.
- Refactorización parcial: Adaptación selectiva de componentes para aprovechar servicios cloud específicos, manteniendo la arquitectura general.
- Rediseño cloud-native: Reconstrucción completa utilizando servicios gestionados y patrones diseñados específicamente para entornos cloud.
- Implementación híbrida: Combinación de recursos locales y en nube, ideal para organizaciones con grandes inversiones existentes o requisitos especiales de latencia/cumplimiento.
La elección no tiene que ser única para toda la organización; diferentes sistemas pueden seguir distintas aproximaciones según sus características particulares.
Estrategias de Migración Efectivas
La migración de datos representa frecuentemente el mayor desafío técnico. Dependiendo del volumen, criticidad y ventanas de mantenimiento disponibles, puedes considerar:
- Migración offline: Ideal para conjuntos de datos pequeños o sistemas que pueden permitirse interrupciones.
- Replicación continua: Establece sincronización entre sistemas origen y destino, minimizando el tiempo de inactividad durante la transición.
- Migración progresiva: Traslada datos y funcionalidades incrementalmente, validando cada etapa antes de proceder.
- Enfoque de strangler fig: Rodea gradualmente sistemas legacy con nuevas implementaciones cloud, redirigiendo tráfico progresivamente hasta poder desmantelar completamente el sistema original.
Herramientas especializadas como AWS Database Migration Service, Azure Database Migration Service o soluciones de terceros como Striim o Talend pueden automatizar gran parte del proceso, reduciendo riesgos y esfuerzo manual.
Optimización de Costos y Rendimiento
Una vez en la nube, la gestión proactiva de recursos resulta crítica para mantener un equilibrio óptimo entre costos y rendimiento:
- Implementa sistemas de monitorización exhaustiva para identificar patrones de uso y oportunidades de optimización.
- Utiliza instancias reservadas o compromisos de uso para cargas de trabajo predecibles, obteniendo descuentos significativos.
- Configura escalado automático basado en métricas de rendimiento real, no en estimaciones.
- Aprovecha capacidades de hibernación o reducción automática durante periodos de baja actividad.
- Considera la implementación de políticas de ciclo de vida de datos, trasladando información histórica a almacenamiento más económico.
Garantizando Seguridad y Cumplimiento
El modelo de responsabilidad compartida requiere una estrategia de seguridad adaptada al entorno cloud:
- Implementa cifrado consistente en reposo y en tránsito para todos los datos sensibles.
- Establece controles de acceso basados en el principio de mínimo privilegio, utilizando servicios de identidad nativos de la nube.
- Configura redes privadas virtuales y puntos de enlace privados para minimizar la exposición pública.
- Activa auditoría completa de todas las operaciones sobre datos sensibles.
- Utiliza herramientas de detección de amenazas y anomalías específicas para entornos cloud.
- Implementa procesos formales de evaluación de seguridad para nuevos servicios antes de su adopción.
Gestión del Cambio Organizativo
El aspecto humano de la transición resulta tan importante como el técnico:
- Invierte en capacitación específica para equipos técnicos en tecnologías cloud relevantes.
- Establece centros de excelencia o equipos de evangelización que aceleren la transferencia de conocimiento.
- Revisa y adapta procesos operativos para reflejar las nuevas capacidades y responsabilidades.
- Comunica clara y consistentemente los beneficios esperados y los cambios que experimentarán distintos grupos de usuarios.
Tendencias Futuras en Bases de Datos en la Nube
El ecosistema de bases de datos en la nube continúa evolucionando a un ritmo vertiginoso, impulsado por avances tecnológicos y cambios en las necesidades empresariales. Comprender las tendencias emergentes resulta fundamental para organizaciones que buscan mantenerse competitivas y aprovechar nuevas oportunidades.
Bases de Datos Sin Servidor (Serverless)
Las bases de datos serverless representan la siguiente frontera en la abstracción de infraestructura. Estos servicios eliminan completamente la necesidad de aprovisionar o gestionar servidores, escalando automáticamente desde cero hasta miles de operaciones por segundo en función de la demanda real. AWS Aurora Serverless, Firebase Realtime Database y MongoDB Atlas Serverless son ejemplos destacados de esta tendencia.
La facturación por operación o consumo real (no por capacidad reservada) hace que estos servicios sean extremadamente eficientes para cargas de trabajo variables o intermitentes. Para startups y aplicaciones en fases iniciales, este modelo permite minimizar costos mientras se establece la base de usuarios, pagando literalmente sólo por el valor generado.
Inteligencia Artificial Integrada
La integración de capacidades de inteligencia artificial directamente en las bases de datos está transformando su papel en la arquitectura empresarial. Servicios como Azure Cosmos DB con Azure Cognitive Search o Amazon Aurora con Amazon Comprehend permiten realizar análisis de sentimiento, extracción de entidades o clasificación de contenido directamente dentro del motor de base de datos.
Esta fusión elimina la necesidad de mover grandes volúmenes de datos entre sistemas para su análisis, reduciendo latencia y complejidad arquitectónica. En un futuro cercano, veremos cómo las bases de datos evolucionan de simples repositorios pasivos a componentes activos capaces de extraer automáticamente insights y generar valor de negocio.
Multi-nube y Portabilidad
Ante la preocupación creciente por la dependencia de proveedores específicos, están surgiendo soluciones diseñadas para operar de manera consistente en múltiples nubes. Servicios como Cockroach Labs CockroachDB Cloud, MongoDB Atlas o Redis Enterprise Cloud ofrecen experiencias unificadas independientemente del proveedor de infraestructura subyacente.
Esta flexibilidad permite a las organizaciones distribuir cargas de trabajo entre proveedores según consideraciones de precio, rendimiento o disponibilidad regional, sin necesidad de refactorizar aplicaciones. La estandarización de interfaces como Kubernetes está acelerando esta tendencia hacia un futuro donde la nube se convierte en un commodity intercambiable.
Procesamiento Híbrido Transaccional-Analítico (HTAP)
Tradicionalmente, las organizaciones han mantenido sistemas separados para procesamiento transaccional (OLTP) y analítico (OLAP), con costosos procesos ETL entre ambos. Las bases de datos HTAP emergentes como SingleStore DB, Snowflake y Amazon DynamoDB con Amazon Redshift Integration rompen esta dicotomía, permitiendo realizar análisis complejos directamente sobre datos operacionales en tiempo real.
Esta convergencia elimina latencias, reduce costos de replicación y garantiza que las decisiones se tomen sobre datos actualizados al instante. Para industrias como comercio electrónico, servicios financieros o IoT industrial, donde los microsegundos importan, esta capacidad representa una ventaja competitiva significativa.
Edge Computing y Bases de Datos Distribuidas
El crecimiento explosivo de dispositivos conectados y aplicaciones que requieren respuestas en tiempo real está impulsando un modelo donde el procesamiento de datos ocurre más cerca de su origen, en el «borde» de la red. Soluciones como AWS Wavelength, Azure Edge Zones o Cloudflare Workers KV permiten desplegar bases de datos en ubicaciones físicamente próximas a los usuarios finales.
Esta arquitectura distribuida reduce drásticamente la latencia y mejora la experiencia de usuario en aplicaciones sensibles al tiempo como juegos online, streaming o aplicaciones de realidad aumentada. Además, facilita el cumplimiento de regulaciones de localización de datos sin sacrificar rendimiento.
Bases de Datos Cuánticas
Aunque aún en fases experimentales, las bases de datos cuánticas representan el horizonte más disruptivo en este campo. Compañías como D-Wave y IBM están explorando cómo los principios de la computación cuántica podrían aplicarse al almacenamiento y procesamiento de datos, potencialmente revolucionando operaciones como búsquedas complejas, optimización y análisis de patrones en conjuntos de datos masivos.
Mientras los ordenadores cuánticos prácticos y accesibles aún están en desarrollo, ya existen simuladores y sistemas híbridos que permiten a organizaciones visionarias experimentar con estas tecnologías y prepararse para un futuro donde los límites actuales de procesamiento de información podrían quedar obsoletos.
Preguntas Frecuentes sobre Bases de Datos en la Nube
1. ¿Cuál es la diferencia entre bases de datos en la nube y bases de datos tradicionales?
Las bases de datos en la nube se ejecutan en infraestructuras gestionadas por proveedores especializados, accesibles a través de internet, mientras que las bases de datos tradicionales normalmente operan en servidores físicos dentro de las instalaciones de la organización. Las soluciones cloud ofrecen escalabilidad automática, alta disponibilidad geográfica y un modelo de pago por uso, eliminando la necesidad de gestionar hardware o centros de datos. Sin embargo, las bases de datos tradicionales pueden ofrecer mayor control, personalización avanzada y rendimiento más predecible en algunos escenarios específicos.
2. ¿Qué tipo de base de datos en la nube debería elegir para mi proyecto?
La elección depende principalmente de tus requisitos específicos. Para aplicaciones con relaciones complejas y transacciones que requieren propiedades ACID, las bases de datos relacionales como Aurora, Cloud SQL o Azure SQL Database suelen ser apropiadas. Para aplicaciones web con esquemas variables o que necesitan escalabilidad horizontal masiva, soluciones NoSQL como MongoDB Atlas o DynamoDB podrían ser mejores. Aplicaciones que requieren análisis de grandes volúmenes de datos se beneficiarán de data warehouses como Redshift o BigQuery. Es fundamental analizar patrones de acceso, modelo de datos, requisitos de consistencia y escalabilidad antes de tomar una decisión.
3. ¿Son seguras las bases de datos en la nube para información sensible?
Sí, con la configuración adecuada. Los principales proveedores de servicios cloud implementan medidas de seguridad que suelen superar las capacidades de la mayoría de centros de datos corporativos, incluyendo cifrado avanzado, controles de acceso granulares, protección contra amenazas y cumplimiento certificado con estándares internacionales. Sin embargo, la seguridad en la nube sigue un modelo de responsabilidad compartida donde el cliente debe configurar correctamente permisos, implementar prácticas seguras de desarrollo y mantener controles de acceso apropiados. Para datos extremadamente sensibles, existen opciones adicionales como claves de cifrado gestionadas por el cliente (BYOK) o instancias aisladas.
4. ¿Cómo afecta la latencia de internet al rendimiento de bases de datos en la nube?
La latencia de red puede impactar significativamente el rendimiento, especialmente para aplicaciones que realizan numerosas consultas pequeñas o requieren respuestas en tiempo real. Los principales proveedores mitigan este problema ofreciendo múltiples regiones geográficas y zonas de disponibilidad que permiten ubicar datos cerca de los usuarios. Tecnologías como Content Delivery Networks (CDN), caching distribuido y arquitecturas edge computing pueden reducir aún más el impacto de la latencia. Para aplicaciones extremadamente sensibles a este factor, soluciones híbridas con componentes locales pueden ser apropiadas.
5. ¿Qué consideraciones regulatorias debo tener en cuenta al migrar a bases de datos en la nube?
Las regulaciones varían significativamente según la industria y región geográfica. Normativas como GDPR en Europa, HIPAA para información médica en EE.UU. o LGPD en Brasil imponen requisitos específicos sobre localización de datos, consentimiento, retención y transferencias internacionales. Es fundamental realizar un análisis de cumplimiento considerando el tipo de información almacenada, ubicación de usuarios y requisitos sectoriales específicos. Los principales proveedores ofrecen regiones específicas con certificaciones de cumplimiento y herramientas para gestionar requisitos regulatorios, pero la responsabilidad última sigue recayendo en la organización propietaria de los datos.
6. ¿Cómo puedo estimar y controlar los costos de bases de datos en la nube?
La estimación de costos debe considerar múltiples factores: almacenamiento, transferencia de datos, operaciones de lectura/escritura, recursos de computación y servicios adicionales como copias de seguridad o replicación. Los principales proveedores ofrecen calculadoras de precios que permiten simulaciones detalladas basadas en patrones de uso esperados. Para control continuo, implementa presupuestos y alertas automatizadas, utiliza etiquetado consistente para atribución de costos, aprovecha descuentos por compromiso de uso para cargas predecibles, y considera usar instancias más pequeñas con escalado automático en lugar de sobredimensionar recursos. Herramientas de terceros como CloudHealth, Cloudability o ParkMyCloud pueden proporcionar visibilidad adicional y recomendaciones de optimización.
Casos de Éxito en la Implementación de Bases de Datos en la Nube
El impacto transformador de las bases de datos en la nube se aprecia mejor a través de ejemplos concretos de organizaciones que han aprovechado estas tecnologías para resolver desafíos reales y generar valor tangible. Estos casos muestran no solo los beneficios técnicos, sino también las implicaciones estratégicas y de negocio.
Transformación de Comercio Electrónico Global
Una empresa minorista internacional enfrentaba severos desafíos con su plataforma de comercio electrónico basada en infraestructura tradicional. Durante eventos promocionales, los sistemas se saturaban frecuentemente, provocando caídas que costaban millones en ventas perdidas. Además, la expansión a nuevos mercados internacionales resultaba prohibitivamente costosa debido a los requisitos de infraestructura local.
La migración de su base de datos principal a una solución distribuida en la nube transformó radicalmente su operación. La plataforma implementó una arquitectura multi-región utilizando Amazon Aurora con replicación global, complementada con Amazon ElastiCache para gestión de sesiones y caché de productos.
Los resultados fueron impresionantes: capacidad para gestionar picos de tráfico 30 veces superiores al promedio sin degradación de rendimiento, reducción del 99,9% en incidentes de disponibilidad y disminución del tiempo de carga en mercados internacionales de 3,2 segundos a menos de 800 milisegundos. Este rendimiento mejorado se tradujo en un incremento del 17% en la tasa de conversión y un aumento del 21% en el valor promedio de compra.
Innovación en Servicios Financieros
Un banco tradicional con sistemas legacy desarrollados en los años 90 luchaba por competir con nuevas fintech más ágiles. Sus ciclos de desarrollo se medían en meses, mientras que los competidores lanzaban nuevas funcionalidades cada semana. La rigidez de sus sistemas le impedía personalizar ofertas y experimentar con nuevos servicios.
La transformación comenzó con la implementación de una estrategia de datos basada en Event Sourcing y CQRS (Command Query Responsibility Segregation) utilizando Azure Cosmos DB como almacén de eventos y Azure Synapse Analytics para análisis en tiempo real. Esta arquitectura permitió desacoplar sistemas core bancarios de las interfaces de cliente, creando una capa de innovación ágil sobre infraestructura tradicional.
El tiempo de desarrollo para nuevas funcionalidades se redujo de meses a días, permitiendo responder rápidamente a tendencias del mercado. La capacidad analítica mejorada habilitó modelos de riesgo y ofertas personalizadas en tiempo real, incrementando la aprobación de préstamos en un 22% mientras se reducía la morosidad en un 14%. El banco pudo lanzar una aplicación móvil completamente renovada que rápidamente alcanzó una puntuación de 4.7/5 en app stores, revirtiendo la tendencia de pérdida de clientes jóvenes.
Escalabilidad para Plataformas Educativas
Una plataforma de educación online experimentó un crecimiento explosivo durante la pandemia, pasando de 50,000 a más de 5 millones de estudiantes activos en menos de tres meses. Su infraestructura existente, basada en servidores dedicados, colapsó repetidamente ante este incremento sin precedentes.
La migración urgente a una arquitectura completamente serverless basada en Google Cloud Firestore para datos operacionales, BigQuery para análisis y Cloud Spanner para gestión de catálogos permitió no solo sobrevivir a este crecimiento sino aprovecharlo estratégicamente. La plataforma ahora escala automáticamente desde prácticamente cero durante horas de baja actividad hasta millones de conexiones simultáneas en picos, manteniendo costos alineados con los ingresos generados.
La elasticidad y el modelo de pago por uso permitieron a esta startup conservar capital crucial durante su fase de hipercrecimiento, evitando inversiones masivas en infraestructura que habrían diluido significativamente el capital de los fundadores. Actualmente, la plataforma procesa más de 8 petabytes de datos mensuales con un equipo técnico de solo 12 personas, manteniendo una disponibilidad del 99.99%.
Optimización Industrial con IoT y Edge Computing
Un fabricante industrial implementó sensores IoT en miles de equipos de producción distribuidos globalmente, generando terabytes de datos diarios. El desafío consistía en analizar esta información para predecir fallos de equipos y optimizar mantenimiento, pero la transferencia de todos estos datos a un centro centralizado resultaba prohibitivamente costosa y lenta.
La solución combinó bases de datos edge en instalaciones locales utilizando Azure SQL Edge con sincronización selectiva a Azure Synapse en la nube. Los algoritmos de machine learning se ejecutan parcialmente en dispositivos edge para detección de anomalías en tiempo real, enviando a la nube solo datos condensados y eventos relevantes para análisis más profundos.
Esta arquitectura híbrida redujo los costos de transferencia de datos en un 94% mientras disminuía la latencia de detección de problemas críticos de minutos a segundos. El sistema ha permitido implementar mantenimiento predictivo que ha reducido el tiempo de inactividad no planificado en un 73%, con un impacto financiero estimado de €43 millones anuales en producción adicional.
Estrategias de Migración a Bases de Datos en la Nube
La transición hacia bases de datos en la nube representa un viaje estratégico que debe planearse cuidadosamente para minimizar riesgos y maximizar beneficios. Existen múltiples enfoques, cada uno con ventajas e inconvenientes específicos según el contexto organizacional.
Evaluación y Descubrimiento
Antes de iniciar cualquier migración, es fundamental realizar una evaluación exhaustiva del entorno actual. Esta fase debe incluir:
- Inventario completo de bases de datos: Documenta todas las instancias, incluyendo producción, desarrollo, pruebas y sistemas shadow IT.
- Análisis de dependencias: Identifica todas las aplicaciones y procesos que interactúan con cada base de datos, mapeando flujos de datos e integraciones.
- Caracterización de cargas de trabajo: Establece patrones de uso, picos de actividad, requisitos de latencia y SLAs para cada sistema.
- Identificación de restricciones: Documenta requisitos regulatorios, limitaciones técnicas y consideraciones de seguridad específicas.
Esta evaluación inicial proporciona la base para decisiones informadas sobre priorización, selección de servicios y estrategias de migración específicas.
Estrategias de Migración Principales
Lift-and-Shift (Rehosting)
Este enfoque implica migrar bases de datos existentes a la nube con cambios mínimos, esencialmente replicando la configuración actual en infraestructura virtual. Es ideal para:
- Migraciones rápidas con plazos ajustados (como abandono de centros de datos)
- Sistemas legacy complejos donde la refactorización representa riesgos significativos
- Organizaciones que buscan familiarizarse con operaciones cloud antes de transformaciones más profundas
Servicios como AWS Database Migration Service, Azure Database Migration Service o Google Database Migration Service pueden automatizar gran parte de este proceso, reduciendo riesgos y tiempo de inactividad.
Replatforming (Lift-Tinker-and-Shift)
Esta estrategia implica realizar ajustes moderados durante la migración para aprovechar algunas ventajas cloud sin rediseños mayores:
- Migración de Oracle a PostgreSQL manteniendo estructura general pero aprovechando menor costo
- Transición de SQL Server auto-gestionado a Azure SQL Database gestionado
- Cambio de MySQL en servidores físicos a Amazon Aurora compatible con MySQL
Este enfoque equilibra beneficios cloud con riesgos y esfuerzos controlados, siendo especialmente útil para organizaciones con mezcla de aplicaciones modernas y legacy.
Refactorización (Rearchitecting)
Implica rediseñar aplicaciones y bases de datos para arquitecturas cloud-native. Aunque más compleja y costosa inicialmente, ofrece máximos beneficios a largo plazo:
- División de monolitos en microservicios con bases de datos dedicadas
- Adopción de patrones Event Sourcing con bases de datos especializadas para distintas vistas
- Implementación de arquitecturas sin servidor (serverless) y bases de datos escalables automáticamente
Esta aproximación resulta ideal para aplicaciones críticas donde rendimiento, escalabilidad y reducción de costos operativos justifican la inversión inicial.
Estrategia Híbrida y Progresiva
Para muchas organizaciones, especialmente con grandes portfolios de aplicaciones, un enfoque híbrido resulta más práctico:
- Iniciar con sistemas no críticos usando lift-and-shift para desarrollar experiencia
- Aplicar replatforming a aplicaciones de valor medio donde beneficios justifiquen esfuerzos moderados
- Reservar refactorización completa para sistemas estratégicos donde transformación digital genera ventajas competitivas
- Mantener temporalmente algunos sistemas en infraestructura tradicional cuando restricciones específicas lo requieran
Este enfoque permite distribuir riesgos, costos y aprendizaje organizacional a lo largo del tiempo.
Gestión de Datos Durante la Migración
La transferencia de datos representa frecuentemente el mayor desafío técnico y logístico. Las principales estrategias incluyen:
Migración Offline (Cold Migration)
Implica detener completamente el sistema origen, exportar datos, transferirlos y cargarlos en el destino. Adecuada para:
- Bases de datos pequeñas donde tiempo de inactividad es aceptable
- Sistemas con baja criticidad empresarial
- Entornos de desarrollo o pruebas
Sincronización Continua (Online Migration)
Establece replicación entre sistemas origen y destino, sincronizando cambios continuamente hasta el momento de transición:
- Ideal para sistemas críticos con requisitos de alta disponibilidad
- Permite validación exhaustiva antes de la transición final
- Facilita retorno rápido a configuración original si surgen problemas
Herramientas como AWS DMS con Change Data Capture (CDC), Striim o Debezium pueden facilitar este proceso manteniendo sistemas sincronizados durante periodos extendidos.
Migración por Fases (Phased Migration)
Traslada subconjuntos de datos o funcionalidades progresivamente:
- División por módulos funcionales o unidades de negocio
- Separación por antigüedad o frecuencia de acceso
- Migración por regiones geográficas o segmentos de clientes
Este enfoque reduce riesgos y permite validar componentes individuales, aunque incrementa complejidad durante el periodo de coexistencia.
Validación y Optimización Posterior a la Migración
El trabajo no concluye con la transferencia inicial de datos. La fase post-migración resulta crítica para garantizar éxito a largo plazo:
- Verificación exhaustiva de integridad: Compara datos y comportamiento entre sistemas origen y destino.
- Monitorización de rendimiento: Establece líneas base y detecta desviaciones para ajuste precoz.
- Optimización progresiva: Identifica oportunidades para aprovechar características nativas de servicios cloud.
- Documentación y transferencia de conocimiento: Garantiza que equipos operativos comprenden nuevas arquitecturas y prácticas.
Conclusión: El Futuro de los Datos Empresariales en la Nube
Las bases de datos en la nube han evolucionado de ser simplemente una alternativa tecnológica a convertirse en un imperativo estratégico para organizaciones que buscan mantener competitividad en la economía digital. A medida que avanzamos hacia un futuro donde datos e inteligencia artificial definen ventajas competitivas sostenibles, la flexibilidad, escalabilidad y capacidades avanzadas de estas plataformas resultan cada vez más decisivas.
La transición no se trata únicamente de cambiar la ubicación física de los datos, sino de transformar fundamentalmente cómo las organizaciones crean valor a partir de ellos. Las empresas más exitosas están utilizando bases de datos en la nube no solo como repositorios pasivos, sino como motores activos de innovación que impulsan nuevos modelos de negocio, experiencias de cliente diferenciadas y eficiencias operativas sin precedentes.
El viaje hacia la nube requiere una visión estratégica clara, planificación meticulosa y disposición para evolucionar continuamente. Las organizaciones deben equilibrar el aprovechamiento de capacidades emergentes con consideraciones prácticas de seguridad, cumplimiento y economía. Aquellas que logren este equilibrio estarán mejor posicionadas para convertir el tsunami de datos que caracteriza nuestra era en inteligencia accionable y ventajas competitivas tangibles.
La verdadera transformación ocurre cuando las bases de datos en la nube dejan de ser percibidas como una preocupación puramente técnica y se integran en conversaciones estratégicas al más alto nivel organizacional. En un mundo donde la agilidad supera consistentemente al tamaño como determinante de éxito empresarial, estas tecnologías proporcionan la infraestructura fundamental para adaptación e innovación continuas.
¿Tu organización está preparada para aprovechar todo el potencial de las bases de datos en la nube? El futuro pertenece a quienes respondan afirmativamente a esta pregunta y actúen decisivamente para hacer realidad esa visión.